

SIMPLIFICATION AND OPTIMIZATION OF I-VECTOR EXTRACTION
Miscellaneous Speaker Identification

Presented by: Ondřej Glembek, Author(s): Ondrej Glembek, Lukas Burget, Pavel Matejka, Martin Karafiát, Brno University of Technology, Czech Republic; Patrick Kenny, CRIM, Canada
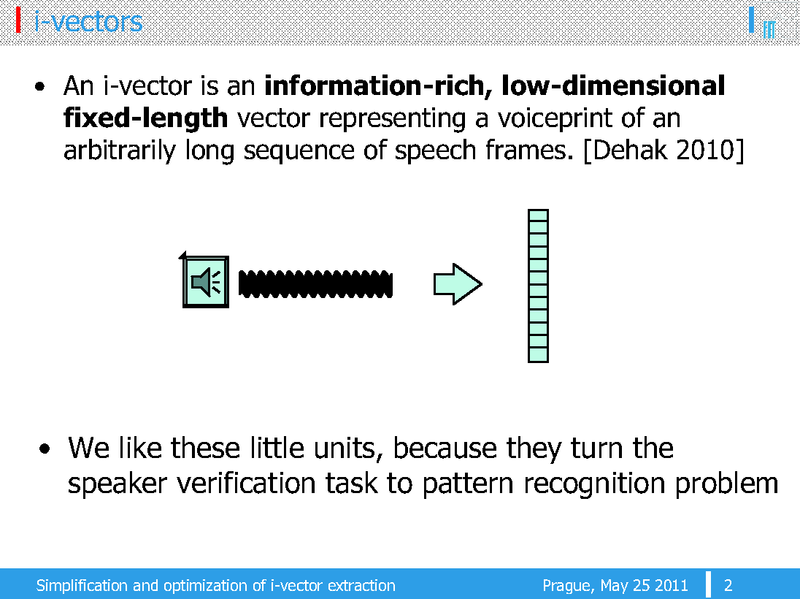
This paper introduces some simplifications to the i-vector speaker recognition systems. I-vector extraction as well as training of the i-vector extractor can be an expensive task both in terms of memory and speed. Under certain assumptions, the formulas for i-vector extraction---also used in i-vector extractor training---can be simplified and lead to a faster and memory more efficient code. The first assumption is that the GMM component alignment is constant across utterances and is given by the UBM GMM weights. The second assumption is that the i-vector extractor matrix can be linearly transformed so that its per-Gaussian components are orthogonal. We use PCA and HLDA to estimate this transform.
Lecture Information
| Recorded: | 2011-05-25 16:35 - 16:55, Panorama |
|---|---|
| Added: | 15. 6. 2011 16:40 |
| Number of views: | 66 |
| Video resolution: | 1024x576 px, 512x288 px |
| Video length: | 0:20:08 |
| Audio track: | MP3 [6.81 MB], 0:20:08 |
Related Lectures
 0:22:35
0:22:35
SPEAKER CHARACTERIZATION USING SPECTRAL SUBBAND ENERGY RATIO BASED ON HARMONIC PLUS NOISE MODEL
Miscellaneous Speaker Identification
Added: 15. 6. 2011 18:05
 0:17:31
0:17:31
AN UTTERANCE COMPARISON MODEL FOR SPEAKER CLUSTERING USING FACTOR ANALYSIS
Miscellaneous Speaker Identification
Added: 15. 6. 2011 16:56
Comments