Continuous Wavelet Vocoder-based Decomposition of Parametric Speech Waveform Synthesis
(3 minutes introduction)
| Mohammed Salah Al-Radhi (BME, Hungary), Tamás Gábor Csapó (BME, Hungary), Csaba Zainkó (BME, Hungary), Géza Németh (BME, Hungary) |
|---|
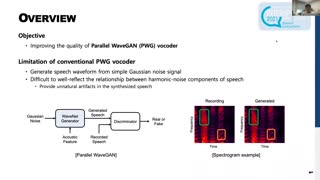
To date, various speech technology systems have adopted the vocoder approach, a method for synthesizing speech waveform that shows a major role in the performance of statistical parametric speech synthesis. However, conventional source-filter systems (i.e., STRAIGHT) and sinusoidal models (i.e., MagPhase) tend to produce over-smoothed spectra, which often result in muffled and buzzy synthesized text-to-speech (TTS). WaveNet, one of the best models that nearly resembles the human voice, has to generate a waveform in a time-consuming sequential manner with an extremely complex structure of its neural networks. WaveNet needs large quantities of voice data before accurate predictions can be obtained. In order to motivate a new, alternative approach to these issues, we present an updated synthesizer, which is a simple signal model to train and easy to generate waveforms, using Continuous Wavelet Transform (CWT) to characterize and decompose speech features. CWT provides time and frequency resolutions different from those of the short-time Fourier transform. It can also retain the fine spectral envelope and achieve high controllability of the structure closer to human auditory scales. We confirmed through experiments that our speech synthesis system was able to provide natural-sounding synthetic speech and outperformed the state-of-the-art WaveNet vocoder.