End-to-end Speech Translation via Cross-modal Progressive Training
(3 minutes introduction)
| Rong Ye (ByteDance, China), Mingxuan Wang (ByteDance, China), Lei Li (ByteDance, China) |
|---|
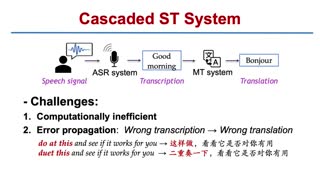
End-to-end speech translation models have become a new trend in research due to their potential of reducing error propagation. However, these models still suffer from the challenge of data scarcity. How to effectively use unlabeled or other parallel corpora from machine translation is promising but still an open problem. In this paper, we propose ''Cross S''peech-''T''ext ''Net''work (''XSTNet''), an end-to-end model for speech-to-text translation. XSTNet takes both speech and text as input and outputs both transcription and translation text. The model benefits from its three key design aspects: a self-supervised pre-trained sub-network as the audio encoder, a multi-task training objective to exploit additional parallel bilingual text, and a progressive training procedure. We evaluate the performance of XSTNet and baselines on the MuST-C En-X and LibriSpeech En-Fr datasets. In particular, XSTNet achieves state-of-the-art results on all language directions with an average BLEU of 28.8, outperforming the previous best method by 3.2 BLEU. Code, models, cases, and more detailed analysis are publicly available.