Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement
(3 minutes introduction)
| Sefik Emre Eskimez (Microsoft, USA), Xiaofei Wang (Microsoft, USA), Min Tang (Microsoft, USA), Hemin Yang (Microsoft, USA), Zirun Zhu (Microsoft, USA), Zhuo Chen (Microsoft, USA), Huaming Wang (Microsoft, USA), Takuya Yoshioka (Microsoft, USA) |
|---|
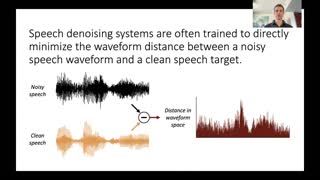
With the surge of online meetings, it has become more critical than ever to provide high-quality speech audio and live captioning under various noise conditions. However, most monaural speech enhancement (SE) models introduce processing artifacts and thus degrade the performance of downstream tasks, including automatic speech recognition (ASR). This paper proposes a multi-task training framework to make the SE models unharmful to ASR. Because most ASR training samples do not have corresponding clean signal references, we alternately perform two model update steps called SE-step and ASR-step. The SE-step uses clean and noisy signal pairs and a signal-based loss function. The ASR-step applies a pre-trained ASR model to training signals enhanced with the SE model. A cross-entropy loss between the ASR output and reference transcriptions is calculated to update the SE model parameters. Experimental results with realistic large-scale settings using ASR models trained on 75,000-hour data show that the proposed framework improves the word error rate for the SE output by 11.82% with little compromise in the SE quality. Performance analysis is also carried out by changing the ASR model, the data used for the ASR-step, and the schedule of the two update steps.