Intra-Sentential Speaking Rate Control in Neural Text-To-Speech for Automatic Dubbing
(longer introduction)
| Mayank Sharma (Amazon, India), Yogesh Virkar (Amazon, USA), Marcello Federico (Amazon, USA), Roberto Barra-Chicote (Amazon, UK), Robert Enyedi (Amazon, USA) |
|---|
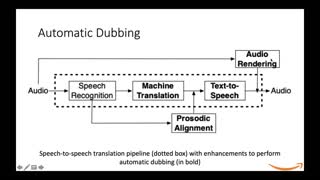
Automatically dubbed speech of a video involves: (i) segmenting the target sentences into phrases to reflect the speech-pause arrangement used by the original speaker, and (ii) adjusting the speaking rate of the synthetic voice at the phrase-level to match the exact timing of each corresponding source phrase. In this work, we investigate a post-segmentation approach to control the speaking rate of neural Text-to-Speech (TTS) at the phrase-level after generating the entire sentence. Our post-segmentation method relies on the attention matrix generated by the context generation step to perform a force-alignment over pause markers inserted in the input text. We show that: (i) our approach can be more accurate than applying an off-the-shelf forced aligner, and (ii) post-segmentation method permits generation more fluent speech than pre-segmentation approach described in [1].