Low Resource German ASR with Untranscribed Data Spoken by Non-native Children - INTERSPEECH 2021 Shared Task SPAPL System
(3 minutes introduction)
| Jinhan Wang (University of California at Los Angeles, USA), Yunzheng Zhu (University of California at Los Angeles, USA), Ruchao Fan (University of California at Los Angeles, USA), Wei Chu (PAII, USA), Abeer Alwan (University of California at Los Angeles, USA) |
|---|
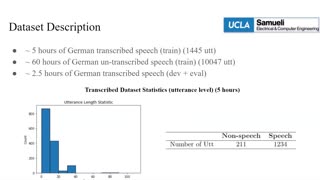
This paper describes the SPAPL system for the INTERSPEECH 2021 Challenge: Shared Task on Automatic Speech Recognition for Non-Native Children’s Speech in German. ~5 hours of transcribed data and ~60 hours of untranscribed data are provided to develop a German ASR system for children. For the training of the transcribed data, we propose a non-speech state discriminative loss (NSDL) to mitigate the influence of long-duration non-speech segments within speech utterances. In order to explore the use of the untranscribed data, various approaches are implemented and combined together to incrementally improve the system performance. First, bidirectional autoregressive predictive coding (Bi-APC) is used to learn initial parameters for acoustic modelling using the provided untranscribed data. Second, incremental semi-supervised learning is further used to iteratively generate pseudo-transcribed data. Third, different data augmentation schemes are used at different training stages to increase the variability and size of the training data. Finally, a recurrent neural network language model (RNNLM) is used for rescoring. Our system achieves a word error rate (WER) of 39.68% on the evaluation data, an approximately 12% relative improvement over the official baseline (45.21%).