Mutual Information Enhanced Training for Speaker Embedding
(3 minutes introduction)
| Youzhi Tu (PolyU, China), Man-Wai Mak (PolyU, China) |
|---|
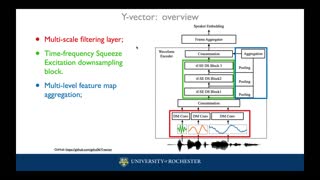
Mutual information (MI) is useful in unsupervised and self-supervised learning. Maximizing the MI between the low-level features and the learned embeddings can preserve meaningful information in the embeddings, which can contribute to performance gains. This strategy is called deep InfoMax (DIM) in representation learning. In this paper, we follow the DIM framework so that the speaker embeddings can capture more information from the frame-level features. However, a straightforward implementation of DIM may pose a dimensionality imbalance problem because the dimensionality of the frame-level features is much larger than that of the speaker embeddings. This problem can lead to unreliable MI estimation and can even cause detrimental effects on speaker verification. To overcome this problem, we propose to squeeze the frame-level features before MI estimation through some global pooling methods. We call the proposed method squeeze-DIM. Although the squeeze operation inevitably introduces some information loss, we empirically show that the squeeze-DIM can achieve performance gains on both Voxceleb1 and VOiCES-19 tasks. This suggests that the squeeze operation facilitates the MI estimation and maximization in a balanced dimensional space, which helps learn more informative speaker embeddings.