Phonetic and Prosodic Information Estimation Using Neural Machine Translation for Genuine Japanese End-to-End Text-to-Speech
(3 minutes introduction)
| Naoto Kakegawa (Okayama University, Japan), Sunao Hara (Okayama University, Japan), Masanobu Abe (Okayama University, Japan), Yusuke Ijima (NTT, Japan) |
|---|
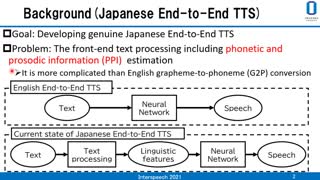
The biggest obstacle to develop end-to-end Japanese text-to-speech (TTS) systems is to estimate phonetic and prosodic information (PPI) from Japanese texts. The following are the reasons: (1) the Kanji characters of the Japanese writing system have multiple corresponding pronunciations, (2) there is no separation mark between words, and (3) an accent nucleus must be assigned at appropriate positions. In this paper, we propose to solve the problems by neural machine translation (NMT) on the basis of encoder-decoder models, and compare NMT models of recurrent neural networks and the Transformer architecture. The proposed model handles texts on token (character) basis, although conventional systems handle them on word basis. To ensure the potential of the proposed approach, NMT models are trained using pairs of sentences and their PPIs that are generated by a conventional Japanese TTS system from 5 million sentences. Evaluation experiments were performed using PPIs that are manually annotated for 5,142 sentences. The experimental results showed that the Transformer architecture has the best performance, with 98.0% accuracy for phonetic information estimation and 95.0% accuracy for PPI estimation. Judging from the results, NMT models are promising toward end-to-end Japanese TTS.