Pre-training for Spoken Language Understanding with Joint Textual and Phonetic Representation Learning
(3 minutes introduction)
| Qian Chen (Alibaba, China), Wen Wang (Alibaba, China), Qinglin Zhang (Alibaba, China) |
|---|
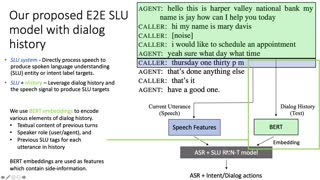
In the traditional cascading architecture for spoken language understanding (SLU), it has been observed that automatic speech recognition errors could be detrimental to the performance of natural language understanding. End-to-end (E2E) SLU models have been proposed to directly map speech input to desired semantic frame with a single model, hence mitigating ASR error propagation. Recently, pre-training technologies have been explored for these E2E models. In this paper, we propose a novel joint textual-phonetic pre-training approach for learning spoken language representations, aiming at exploring the full potentials of phonetic information to improve SLU robustness to ASR errors. We explore phoneme labels as high-level speech features, and design and compare pre-training tasks based on conditional masked language model objectives and inter-sentence relation objectives. We also investigate the efficacy of combining textual and phonetic information during fine-tuning. Experimental results on spoken language understanding benchmarks, Fluent Speech Commands and SNIPS, show that the proposed approach significantly outperforms strong baseline models and improves robustness of spoken language understanding to ASR errors.