Serialized Multi-Layer Multi-Head Attention for Neural Speaker Embedding
(3 minutes introduction)
| Hongning Zhu (NUS, Singapore), Kong Aik Lee (A*STAR, Singapore), Haizhou Li (NUS, Singapore) |
|---|
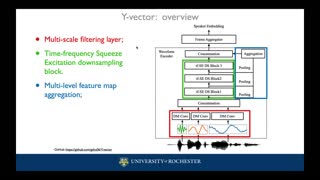
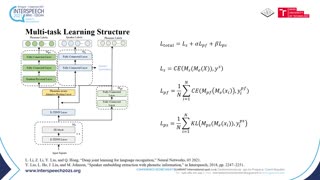
This paper proposes a serialized multi-layer multi-head attention for neural speaker embedding in text-independent speaker verification. In prior works, frame-level features from one layer are aggregated to form an utterance-level representation. Inspired by the Transformer network, our proposed method utilizes the hierarchical architecture of stacked self-attention mechanisms to derive refined features that are more correlated with speakers. Serialized attention mechanism contains a stack of self-attention modules to create fixed-dimensional representations of speakers. Instead of utilizing multi-head attention in parallel, the proposed serialized multi-layer multi-head attention is designed to aggregate and propagate attentive statistics from one layer to the next in a serialized manner. In addition, we employ an input-aware query for each utterance with the statistics pooling. With more layers stacked, the neural network can learn more discriminative speaker embeddings. Experiment results on VoxCeleb1 dataset and SITW dataset show that our proposed method outperforms other baseline methods, including x-vectors and other x-vectors + conventional attentive pooling approaches by 9.7% in EER and 8.1% in DCF10-2.