Towards simultaneous machine interpretation
(3 minutes introduction)
| Alejandro Pérez-González-de-Martos (Universitat Politècnica de València, Spain), Javier Iranzo-Sánchez (Universitat Politècnica de València, Spain), Adrià Giménez Pastor (Universitat Politècnica de València, Spain), Javier Jorge (Universitat Politècnica de València, Spain), Joan-Albert Silvestre-Cerdà (Universitat Politècnica de València, Spain), Jorge Civera (Universitat Politècnica de València, Spain), Albert Sanchis (Universitat Politècnica de València, Spain), Alfons Juan (Universitat Politècnica de València, Spain) |
|---|
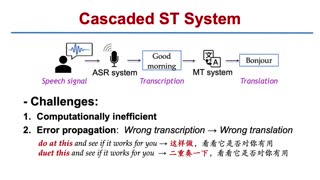
Automatic speech-to-speech translation (S2S) is one of the most challenging speech and language processing tasks, especially when considering its application to real-time settings. Recent advances on streaming Automatic Speech Recognition (ASR), simultaneous Machine Translation (MT) and incremental neural Text-To-Speech (TTS) make it possible to develop real-time cascade S2S systems with greatly improved accuracy. On the way to simultaneous machine interpretation, a state-of-the-art cascade streaming S2S system is described and empirically assessed in the simultaneous interpretation of European Parliament debates. We pay particular attention to the TTS component, particularly in terms of speech naturalness under a variety of response-time settings, as well as in terms of speaker similarity for its cross-lingual voice cloning capabilities.