Two-Pathway Style Embedding for Arbitrary Voice Conversion
(3 minutes introduction)
| Xuexin Xu (Xiamen University, China), Liang Shi (Xiamen University, China), Jinhui Chen (Prefectural University of Hiroshima, Japan), Xunquan Chen (Kobe University, Japan), Jie Lian (Xiamen University, China), Pingyuan Lin (Xiamen University, China), Zhihong Zhang (Xiamen University, China), Edwin R. Hancock (University of York, UK) |
|---|
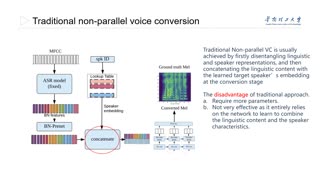
Arbitrary voice conversion, also referred to as zero-shot voice conversion, has recently attracted increased attention in the literature. Although disentangling the linguistic and style representations for acoustic features is an effective way to achieve zero-shot voice conversion, the problem of how to convert to a natural speaker style is challenging because of the intrinsic variabilities of speech and the difficulties of completely decoupling them. For this reason, in this paper, we propose a Two-Pathway Style Embedding Voice Conversion framework (TPSE-VC) for realistic and natural speech conversion. The novel feature of this method is to simultaneously embed sentence-level and phoneme-level style information. A novel attention mechanism is proposed to implement the implicit alignment for timbre style and phoneme content, further embedding a phoneme-level style representation. In addition, we consider embedding the complete set of time steps of audio style into a fixed-length vector to obtain the sentence-level style representation. Moreover, TPSEVC does not require any pre-trained models, and is only trained with non-parallel speech data. Experimental results demonstrate that the proposed TPSE-VC outperforms the state-of-the-art results on zero-shot voice conversion.