Compensation on x-vector for Short Utterance Spoken Language Identification
| Peng Shen, Xugang Lu, Komei Sugiura, Sheng Li, Hisashi Kawai |
|---|
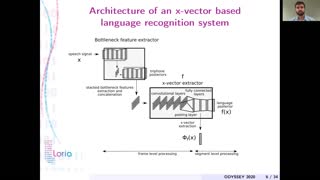
Feature representation based on x-vector has been successfully applied in spoken language identification tasks. However, the performance on short utterances is severely degraded. The degradation is mainly due to the large variation of the x-vector representation for short utterances which results in large model confusion. One of the solutions is to normalize the representations of short utterances with reference to representations of their corresponding long utterances in x-vector space. Different from previous work, both mean and variance statistic components in the x-vector are normalized for speaker recognition task, we argue that variance component in the x-vector encodes discriminative information of languages which should not be normalized for short utterances. Based on this consideration, we proposed an x-vector extraction model for short utterance with adding compensation constraint only for the mean component in the x-vector. Experiments on NIST LRE07 dataset were carried out and showed significant improvement on short utterance LID tasks.